

3 �� 18 �գ�������ά��ʽ��Դ�ҵ���ģ̬˼ά������ģ�� Skywork-R1V��������ģ̬˼����ʱ������ Skywork-R1V �״γɹ�ʵ�֡�ǿ�ı������������Ӿ�ģ̬��Ǩ�ơ�֮��������ά�ٶȷ�����������ʽ��Դ��ģ̬����ģ�͵�ȫ�������汾 ���� Skywork-R1V 2.0�����¼�� R1V 2.0) ��
01
R1V 2.0 ����ȫ����������Դ���Ӿ����ı���������˫������
Skywork-R1V 2.0 �ǵ�ǰ��������Ӿ����ı����������Ŀ�Դ��ģ̬ģ�ͣ��ö�ģ̬ģ���ڸ߿�������������������ͨ�������о��������죬����ʵ�ֶ�ģ̬��ģ�͵ġ���� + ��ȡ�ͳһ��������� R1V 2.0 ģ���ľ����㣺
-���ij�������������ѧ����Ŀ����ѧ/����/��ѧ������Ч����Ⱥ���������AI�������֣�
-��Դ�۷���38B Ȩ�� + ��������ȫ�濪Դ���ƶ���ģ̬��̬���裻
-�������±������ģ̬����ģ�ͣ�SkyworkVL Reward�� �� ���ƫ���Ż����ƣ�MPO����ȫ������ģ�ͷ���������ѡ�����������������ƣ�SSB����ͻ��ǿ��ѧϰ��������ʧ��ƿ����
�ڶ��Ȩ���������У�R1V 2.0 ����� R1V 1.0 ���ı����Ӿ����������о�ʵ������Ծ����������רҵ������������ѧ��������̾�������ѧ����������ͨ�������紴��д���뿪��ʽ�ʴ�R1V 2.0 �����ֳ����߾������ı��֣�
-�� MMMU ��ȡ�� 73.6 �֣�ˢ�¿�Դ SOTA ��¼��
-�� Olympiad Bench �ϴﵽ 62.6 �֣���������������Դģ�ͣ�
-�� MathVision��MMMU-PRO �� MathVista �ȶ����Ӿ��������о��������죬���������ѿ�������Դ��ҵģ�ͣ����Ƶ�ǰ��Դ��ģ̬����ģ���е�ٮٮ�ߡ�
���뿪Դ��ģ̬ģ�͵ĶԱ��У�R1V 2.0 ���Ӿ��������������ڶԴģ�����ӱ������
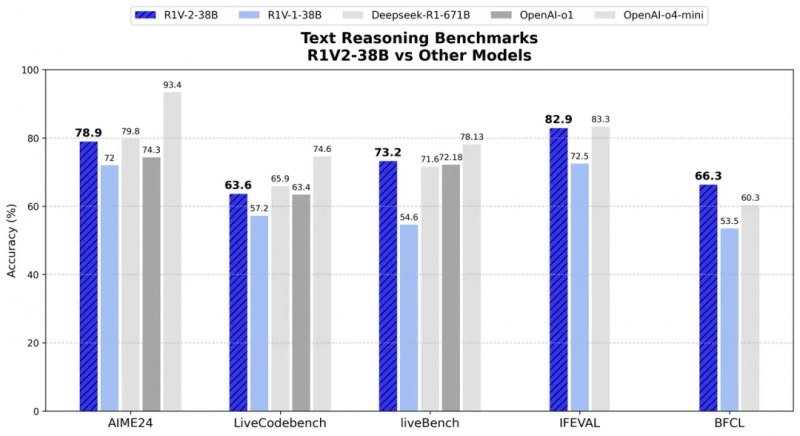
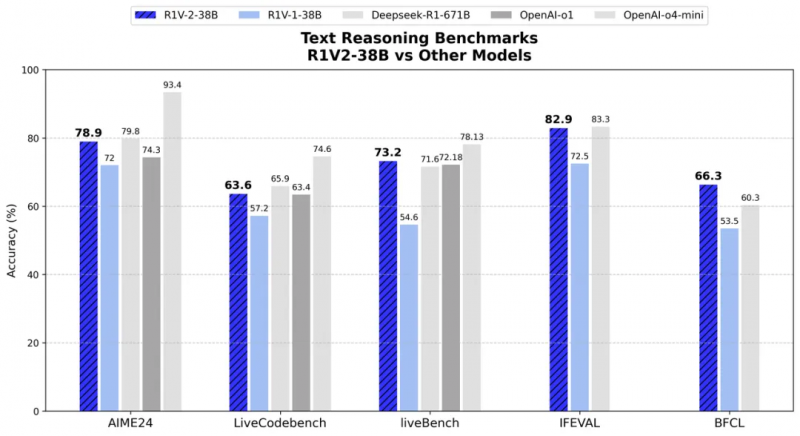
����ͼ��ʾ��R1V2.0 Ҳչ�ֳ�������ҵ��Դ��ģ̬ģ�͵�ʵ����
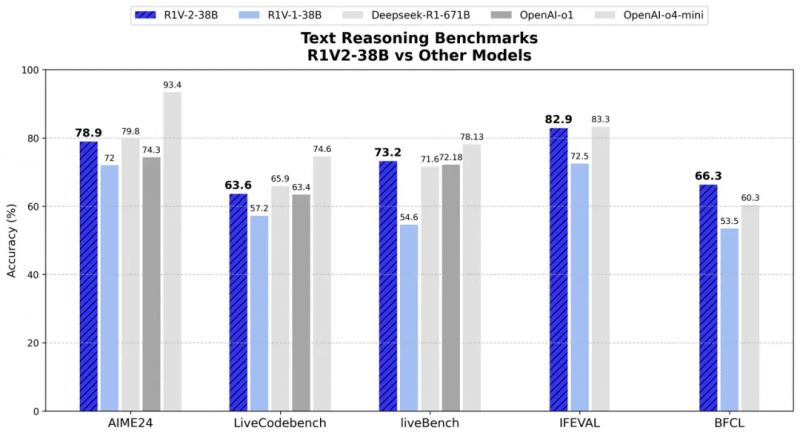
�����ı��������棬�� AIME2024 �� LiveCodeBench ����ս�У�R1V 2.0 �ֱ�ȡ����78.9 �ֺ� 63.6 �֣�չ�ֳ�������ר�Ҽ���ѧ�������������������ר���ı�����ģ�ͶԱ��У�R1V2.0 ͬ��չ�ֳ�Խ���ı�����������
02
��������һ���Ƴ���ģ̬����ģ�� Skywork-VL Reward��ȫ�濪Դ
�� R1V 1.0 ��Դ������������ά�Ŷ��ջ�������ȫ�������о��ߵĹ㷺��������ģ��������������������ͬʱ���Ŷ�Ҳ���֣����ȼ��������������ѵ����������ģ�����������������µı��֣�Ӱ������ķ���������ͨ�ñ��֡�
Ϊʵ�ֶ�ģ̬��ģ���ڡ�����������롰ͨ��������֮������ƽ�⣬R1V 2.0 ������ȫ�µġ���ģ̬����ģ�� Skywork-VL Reward���������������Ļ��ǿ��ѵ�����ơ�����������ǿ����������ͬʱ����һ���ȹ���ģ���ڶ�����ģ̬�����е��ȶ������뷺��������
Skywork-VL Reward��������ģ̬ǿ������ģ����ƪ�£�
��ǰ����ҵ�ж�ģ̬����ģ�͵�ȱ�����ѳ�Ϊǿ��ѧϰ�� VLM��Vision-Language Models�������һ����չ�Ĺؼ�ƿ����
���н���ģ������ȷ���ۿ�ģ̬��������ĸ������������ɹ��̡�Ϊ�ˣ�������ά�Ƴ��� SkyworkVL Rewardģ�ͣ��ȿ�Ϊͨ���Ӿ�����ģ�ͣ�VLM���ṩ�����������źţ����ܾ�������ģ̬����ģ�ͳ��������������������ͬʱҲ������Ϊ���������������Ŵ�ѡ���������
��������ʹ�� Skywork-VL Reward ģ���ڶ�ģ̬ǿ��ѧϰ�����о��й㷺�������ԣ��ٽ��˶�ģ̬ģ�͵�Эͬ��չ��
-��ģ̬�����������������ģ̬������ͨ�ý���ģ�ͣ��ƶ���ģ̬ǿ��ѧϰ��
-��������Ӿ�����ģ�����������е�һ��7B Ȩ���뼼������ȫ�濪Դ��
-�ź�ȫ������֧�ִӶ��ı��������������Ķ�Ԫ�������б�
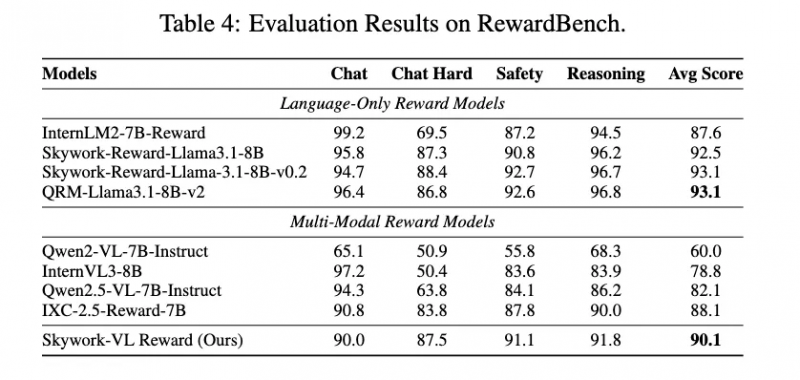
Skywork-VL Reward �ڶ��Ȩ��������б������죺���Ӿ�����ģ������� VL-RewardBench ��ȡ���� 73.1 ��SOTA�ɼ���ͬʱ�ڴ��ı�����ģ������� RewardBench ��Ҳն���˸ߴ� 90.1 �����������ȫ��չʾ�����ڶ�ģ̬���ı������е�ǿ��������
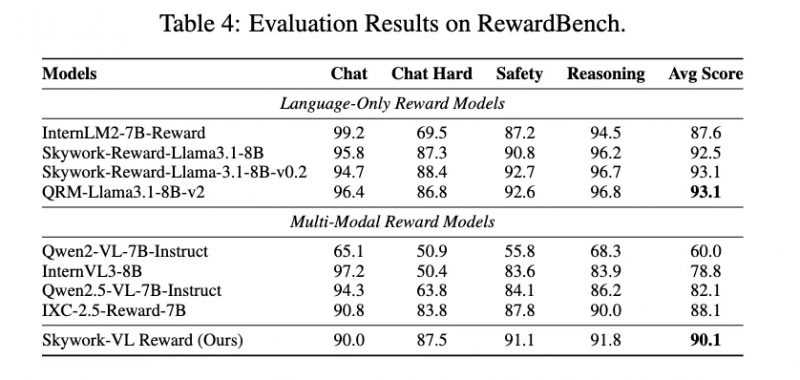
Ϊ������������ҵ���Ŷ�Ҳ�� Skywork-VL Reward ������Դ��
03
�������������������Ż�������������Ч��
������������ģ��ѵ�����١���������������롰ͨ���������֡������Լ�����⡣Ϊ�����һ�������Cͨ�á����������ΰ����⣬�Լ����ͨ������û��ֱ�ӿ���֤�Ĵ𰸵���ս��R1V 2.0 ������ MPO��Mixed Preference Optimization�����ƫ���Ż��� ���ƣ�����ƫ��ѵ���г�ַ��� Skywork-VL Reward ����ģ�͵�ָ�����á�
�� R1V 1.0 ˼·���ƣ�����ʹ����ǰѵ���õ� MLP ��������ֱ�ӽ��Ӿ������� internVIT-6B ��ԭʼ��ǿ��������ģ�� QwQ-32B ���ӣ��γ� R1V 2.0-38B �ij�ʼȨ�ء�����һ����R1V 2.0 ���������߱�һ���Ķ�ģ̬����������
��ͨ������ѵ���Σ�R1V 2.0 ���� Skywork-VL Reward �ṩ��ƫ���źţ�����ģ�ͽ���ƫ��һ�����Ż����Ӷ�ȷ��ģ���ڶ����������¾߱����õ�ͨ����Ӧ������ʵ��֤����Skywork-VL Reward ��Чʵ��������������ͨ��������Эͬ�������ɹ�ʵ�֡��������Ƽ�á���
��ѵ�������������ʱ��R1V 2.0 ��ѵ���в����� ���ڹ����Ⱥ����Բ����Ż�GRPO��Group Relative Policy Optimization�� �������ò���ͨ��ͬ���ѡ��Ӧ֮�����Խ����Ƚϣ�����ģ��ѧ�������ѡ�������·����
R1V 2.0 �����õĶ�ģ̬ǿ��ѵ����������־�Ŵ�ģ��ѵ����ʽ����һ����Ҫ���£�Ҳ�ٴ���֤��ǿ��ѧϰ���˹����������������ĵ�λ��ͨ������ͨ���Ը�ǿ�Ľ���ģ�� Skywork-VL Reward���Լ���Ч�ȶ����������û��� SSB�����Dz�����һ��������R1Vϵ��ģ���ڸ��������е�����������ͬʱҲ����Դģ�Ϳ�ģ̬��������������������ȫ�¸߶ȡ�
R1V 2.0 �ĵ����������ƶ��˿�Դ��ģ̬��ģ���������߽��ϵ�ͻ�ƣ���Ϊ��ģ̬������Ĵ�ṩ���µĻ���ģ�͡�
04
����AGI�ij�����Դ
���һ��������������ά��½����Դ������ģ�ͣ�
��Դϵ����
1. Skywork-R1V ϵ�У�38B �Ӿ�˼ά������ģ�ͣ�������ģ̬˼��ʱ����
2. Skywork-OR1��Open Reasoner 1��ϵ�У�������������ģ�ͣ�7B��32B��ǿ��ѧ��������ģ�ͣ�
3. SkyReelsϵ�У�����AI�̾紴������Ƶ����ģ�ͣ�
4. Skywork-Reward������Խ��ȫ�½���ģ�͡�
��Щ��Ŀ�� Hugging Face �Ϲ��ܻ�ӭ�������˿����������Ĺ㷺��ע���������ۡ�
���Ǽ��ţ���Դ�������£�AGI �ս�������
���� DeepSeek �������Ŷ���չ�ֵ���������Դģ�������ֺ����Դϵͳ�ļ�����࣬����ʵ�ֳ�Խ��R1V 2.0 �����ǵ�ǰ��õĿ�Դ��ģ̬����ģ�ͣ�Ҳ���������� AGI ·�ϵ���һ��Ҫ��̱���������ά���������֡���Դ�����š�����������������Ƴ����ȵĴ�ģ�������ݼ������ܿ����ߡ��ƶ���ҵЭͬ���£�����ͨ���˹����ܣ�AGI����ʵ�ֽ��̡�








