

��Ϊȫ�����ȵ��Ƽ�������ṩ�̣�������������㷺�Ļ�����ʩ�ͷḻ����ҵ���飬��Intel�Ⱥ����������Ӳ���������չ�������������������Ϊ�û��ṩ����Ч�������ܡ����ߵ��Եļ�������������̬�������������������Ƽ��������ʩ��������ҲΪ�Ƽ�����̬ϵͳ�Ĵ��µ춨�˼�ʵ�Ļ�����Ϊ�������Խ���������飬�����Ʋ����������Լ��������Intel ȫ�µ�����GNR��ǿ���������ڵ������������ۺϼ����Լ������ܼ���ȷ�����õ�����ȫ���������������и�ҵ���ֻ�ת�͡�
�����ƵھŴ�������������ECS��
��������GNR�����������еھŴ�������������ʵ����ȫ����������������Խ�����ܡ�������չ�ԺͰ�ȫ�ȶ��ķ������ɽ�Ϊ�û����������ʡ�����Ч���Ƽ������顣����һ����Ʒ��ȣ����ڲ�ͬ�����������ص����������ߴ�2�����ϣ���Ч�����ߴ�40%~110%���ڱȽϳ����ķ�����ʹ����40%������£���Ч��߿�����90%�������ض�ǿ���ڴ�MRDIMM�����ݴ������ʸߴ�8800MT/s���ڴ���������ߴ�2.3�����ڿ�ѧ������AIӦ���пɴ���30%���ϵ�����������
���⣬�ھŴ����������������ö��ּ������棬AMX��Advanced Matrix Extensions����������չ��������������CPU�����ѧϰѵ�����������ܣ���INT8��8λ�����������ͣ���BF16��16λ��������ʽ���⣬��һ��֧�ֻ���FP16��16λ�뾫�ȸ�������ʽ����ģ�ͣ�AVX-512ָ���Advanced Vector Extensions 512�����������ÿʱ�����ڴ�������������QAT��QuickAssist Technology�����������ټ�����֧���������ܺ�ѹ����IAA��In-Memory Analytics Accelerator�����ݷ�����������ж���ڴ�ѹ���ͽ�ѹ����ɨ�輰ѭ������У�顣��������CPU�����ѧϰѵ�����������ܣ����������������ܼ����أ�������Ҫ�������Ӽ�������Ĵ�����ҵ�������ݷ���������ѧϰģ��ѵ���������ṩǿ������֧�֡�
ͬʱ���ھŴ���������������Ӳ��ǿ���İ�ȫ���ԣ��ṩ��������Ӳ�����룬���踴�ӵ�Ӧ�ø��죬ʵ�ָ��ϸ�ļ��ܸ�����ƣ����õر���������ҵ���ݣ�������ļ��ͣ���֤ҵ���������У��ܸ��õظ��ǽ��ڡ�����Ⱥ���Ӧ�ó�����
�����ƾۺϼ��㣨HAC��
�����ƾۺϼ�����һ�ֻ��ڸ�������������ͷ���ػ���������Ӳ���ܹ���ȫ������ۺϼ���ƽ̨���������Դ�Ϊ�����������һ���ƻ�����ʩƽ̨��ƽ̨��Ʒ���������ۺϼ�����������ڴ漴���ػ�������١������ƾۺϼ���ּ�ڴ����ݡ����������оƬ���(EDA)�����ݿ⡢AI ѵ���ȴ����Ӧ�ó�����Ϊ�û��ṩ�����������ܡ��������չ����һ���������
��������GNR�������ṩ�ij�ɫ���ܺͶ�CXL2.0�ڴ�ؼ�����ǿ��֧�֣��������Ƴ��ˡ����ۺϼ������������Ʒ��רΪ�����������ġ��ڴ�ǽ������ơ����ۺϼ���������ܹ�Ϊ�ڴ��ܼ��͵Ĵ����ݼ�AIӦ�������ṩͻ���Ե��Ż�����������������ȷ���û��ڸ��Ӽ��㳡���»��Խ�Ĵ���������Ч�ʡ�
�������Ƴ��ۺϼ����������Ʒ�У�CXL2.0���ٻ���Э���µ��ڴ�ط�����������������Զ���ڴ������ʱ�ɵ��������뼶�������뱾���ڴ�ķ�����ʱ�൱�����ۺϼ������������Ч���ʴ�����߿ɴ�����GB/s�����ܹ�������·�����ڴ�����������ڣ�Ϊ�����ܼ����������ṩԽ�����������ϡ�
�ر�����GNR��������Intel Flat Memory Mode��֧���£�������ݿ�ʹ�����Ӧ�ó�����CXLԶ���ڴ�ķ��������ѽӽ�����DRAMˮƽ���봫ͳEMRƽ̨��ȣ���GNRƽ̨������Spark��Hive�ȹ�������ʱ�������Ƴ��ۺϼ���������ܹ�ʵ��2-4������������������������ִ��ʱ�䡣���⣬��AI/MLѵ�������У���������ǿƽ̨�ܹ����ڴ������ʱ����һ�룬�Ӷ���һ������ѵ���ٶȡ���Щ����ʹ�������Ƴ��ۺϼ����������Ϊ�ڴ��ܼ���Ӧ�õ�����ѡ��
���������������ܼ��㣨E-HPC��
���������ĥ��������E-HPC���Ը����ܼ���ƽ̨ƾ��Խ�ļ������������ĵ�����չ�����������졢оƬ��ơ�������Ϣ��������Ϊ������Ӽ����������ѡƽ̨���������µ�GNR��������E-HPCƽ̨���������˼����ܶȺ����ܱ��֡�
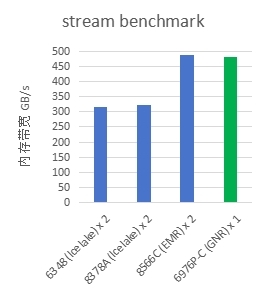
��stream�������У��䱸GNR��������E-HPCƽ̨ƾ�������ڴ�ͨ�����ߵ��ڴ�Ƶ�ʣ���6400 MT/s DDR5�ڴ滷���£���·ʵ���ڴ�����ﵽԼ500GB/s�������һ��EMR��������������������ϵ�����IceLakeʵ��������������������Ԥ����8800 MT/s MRDIMM�����£�˫·ϵͳ����ʵ��1.4TB/s������������HPC���Կ�ѧ����Ϊ�������ڴ����������Ӧ�õļ���Ч�ʡ�
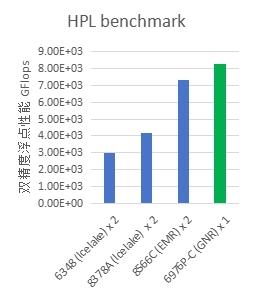
��HPL�������У�ʵ�ⵥ·GNR������˫���ȸ������ܽӽ�8.3 TFlops����Խ����һ��EMR˫·�����ܣ�ˢ����CPU���ܵ��¼�¼�����ȵ���������������������ѵ�������ؿ���ģ���ͼ�����ȼ����ܼ��������ִ��Ч�ʡ�
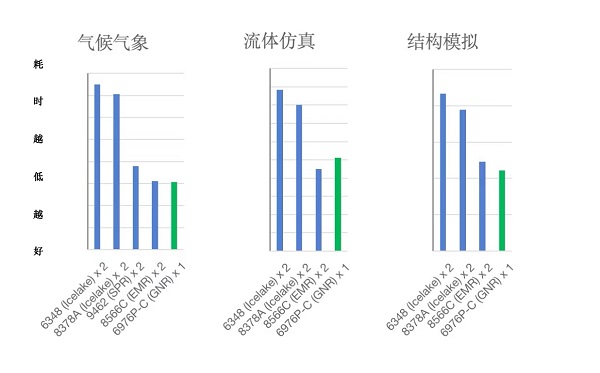
�ڶ������HPCӦ�����������������������ͽṹģ��Ϊ����GNR������ƾ����ǿ��ĵ�оƬ�������ڴ�������ƣ��ڵ�·���Ի�����չ�ֳ���˫·EMR �������ļ���Ч�ʣ�����ζ����˫·GNR�����������£��������ܺ���Դ�����ʽ��������һ�������������������ʵ�ַ���������ͨ����һ��������������E-HPCƽ̨���Ը�������Ԥ��δ����ʵ�����������еı��֣�Ϊ��һ���Ż����ܡ����ͳɱ�����ǿ�����ܶ��ṩ�˿ɿ��Ļ�����
δ�������ǽ��������������Ż������Ǹ���HPCӦ�ó������������ѧ���������Ͽ�ѧģ���Ƶ���ڽ�ģ�ȣ��Խ�һ����֤GNR�������ڸ��ิ�Ӽ��������е�������֡������ڴ���Щ���Խ��Ϊ��ҵ�û��ṩ�����Ż����������ܵ�������ҵ�ͻ���������
������ǰհ
�����ƽ����˹����ܡ������ݷ�������ҵ��Ӧ�õ�����չ�����̽���������Ż������Ƶ��Լ������ܡ����ݴ�����������Ч���֣���Я�ֲ�ҵ�����ͨ�������з�������֧�ֺ���Դ�����ķ�ʽ����ͬ�ƶ���һ���Ƽ�����Ӧ���ռ������������������г�����Ϊ����ҵ�����ֻ�ת���ܡ�




